在一主一备的双M架构中,主备切换只需要把客户端流量切到备库;而在一主多从架构中,主备切换除了要把客户端流量切到备库外,还需要把从库接到新主库上。
主备切换有两种场景,一种是主动切换,一种是被动切换。被动切换,往往是因为主库出问题了,由HA系统发起的。
select 1 判断
select 1成功返回,只能说明这个库的进程还在,并不能说明主库没问题。
1 | set global innodb_thread_concurrency=3;-- 控制InnoDB的并发线程上限,一旦并发线程数达到这个值,InnoDB在接收到新请求的时候,就会进入等待状态,直到有线程退出。 |
| sessionA | sessionB | sessionC | sessionD |
|---|---|---|---|
| select sleep(100) from t; | select sleep(100) from t; | select sleep(100) from t; | |
| select 1;(Query OK)select * from t;(blocked) |
sessionD中,select 1是能执行成功的,但是查询表t的语句会被堵住。用select 1来检测实例是否正常的话,是检测不出问题的。
MHA(Master High Availability)默认使用的方法。另一个可选方案,只做连接,如果连接成功就认为主库没问题。
在InnoDB中,innodb_thread_concurrency这个参数的默认值是0,表示不限制并发线程数量。一个机器的CPU核数有限,不限制并发数,线程全冲进来,上下文切换的成本太高。通常设置为64~128之间的值(理论上是核数的2倍左右最好)。
并发连接与并发查询
show processlist,看到的几千个连接,指的是并发连接;而当前正在执行的语句,才是并发查询。
并发连接数达到几千个影响并不大,多占一些内存而已。应该关注的是并发查询,并发查询太高才是CPU杀手,必须设置innodb_thread_concurrency参数。
在线程进入锁等待以后,并发线程的计数会减一,出现同一行热点更新的问题时,等行锁(也包括间隙锁)的线程是不算在128中的。因为,进入锁等待的线程已经不吃CPU了;另外这样设计,也能避免整个系统锁死。
- 线程1执行begin;update t set c=c+1 where id=1,启动了事务trx1,然后保持这个状态。这个时候,线程处于空闲状态,不算在并发线程里面。
- 线程2到线程129都执行update t set c=c+1 where id=1;由于等待行锁,进入等待状态。这样就有128个线程处于等待状态;
- 如果处于锁等待状态的线程计数不减一,InnoDB就会认为线程数用满了,会阻止其它语句进入引擎执行,这样线程1不能提交事务,而另外128个线程又处于锁等待状态,整个系统就堵住了。
这时InnoDB不能响应任何请求,整个系统被锁死。而且由于所有线程都处于等待状态,此时占用的CPU却是0,不合理。所以遇到进程进入锁等待的情况时,将并发线程的计数减1的设计,是合理而且是必要的。
等锁的线程不算在并发线程计数里,但如果它在真正的执行查询(如select sleep(100) from 1),还是要算进并发线程的计数的。
问题:
同时在执行的语句超过了设置的值,这时候系统其实已经不行了,但是通过select 1来检测系统,会认为系统还是正常的。
查表判断
为了能够检测InnoDB并发线程数过多导致的系统不可用情况,需要找一个访问InnoDB的场景。一般的做法是,在系统库(mysql库)里创建一个表,命名为health_check,里面只放一行数据,然后定期执行:select * from mysql.health_check;使用这个方法,可以检测出由于并发线程过多导致的数据库不可用的情况。
问题:
空间满了以后,这种方法会变得不好使:更新事务要写binlog,一旦binlog所在磁盘的空间占用率达到100%,那么所有的更新语句和事务提交的commit语句就会被堵住,但是,系统这时候还是可以正常读数据的。
更新判断
在表中放一个有意义的字段-timestamp,用来表示最后一次执行检测的时间:update mysql.health_check set t_modified=now();
节点可用性的检测应该包含主库和备库,如果用更新来检测主库,那么备库也要进行更新检测。
备库的检测也是要写binlog的,由于一般会把数据库A和B的主备关系设计为双M结构,所以在备库B上执行的检测命令,也要发回给主库A。但是如果主库A和备库B都用相同的更新命令,就可能出现行冲突,可能会导致主备同步停止。
mysql.health_check这个表就不能只有一行数据了,可以在表上存入多行数据,并用A、B的server_id做主键,保证主、备库各自的检测命令不会发生冲突。
1 | create table 'health_check'( |
问题:判定慢
- 所有的检测逻辑都需要一个超时时间N,执行一条update语句,超过N秒后还不返回,就认为系统不可用。
日志盘的IO利用率已经是100%,整个系统响应非常慢,已经需要做主备切换了。
但是IO利用率100%表示系统的IO是在工作的,每个请求都有机会获得IO资源,执行自己的任务。检测使用的update命令,需要的资源很少,可能在拿到IO资源的时候就可以提交成功,并且在超时时间N秒未到达之前就返回给了检测系统。让检测系统得到”系统正常”的结论。
- 基于外部检测还有一个天然问题,随机性。
外部检测都需要定时轮询,所以系统可能已经出问题了,但是却要等到下一个检测发起执行语句的时候,才有可能发现问题。而且,可能第一次轮询还不能发现,导致切换更慢。
内部统计
MySQL提供内部每一次IO请求的时间,来反映磁盘利用率的问题。
MySQL5.6版本提供performance_schema库,在file_summary_by_event_name表里统计了每次IO请求的时间。
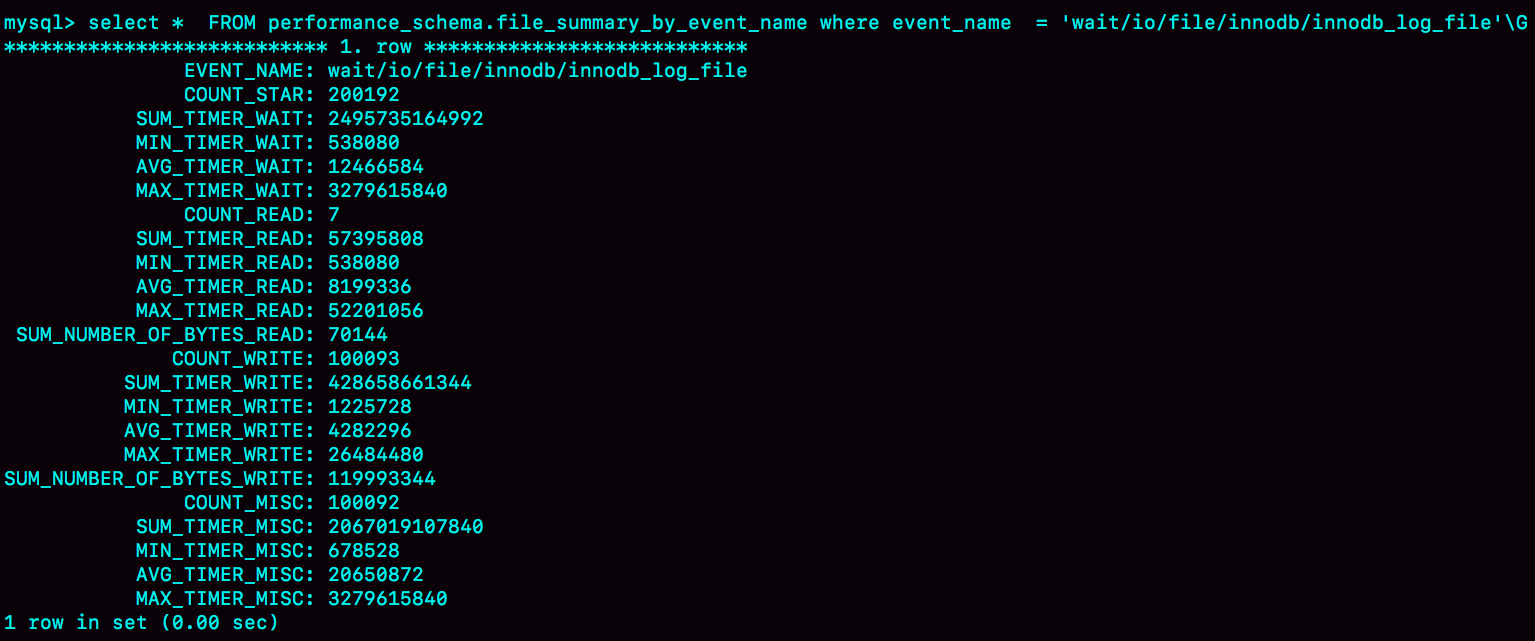
图中表示的是redo log的写入时间。
- 第一列event_name表示统计的类型。
- 接下来有三组数据,显示的是redo log操作的时间统计。
- 第一组5列,是所有IO类型的统计。其中count_star是所有IO的总次数。接下来四列是具体的统计项,单位是皮秒;前缀sum、min、avg、max,分别对应总和、最小值、平均值、最大值。
- 第二组6列,是读操作的统计。最后一列sum_number_of_bytes_read统计的是,总共从redo log里读了多少个字节。
- 第三组6列,统计的是写操作。
- 最后四组数据,是对其他类型数据的统计。在redo log里,是对fsync的统计。
binlog对应的是event_name=’wait/io/file/sql/binlog’这一行。
每一次操作数据库,performance_schema都需要额外的统计这些信息,打开统计功能有性能损耗,打开所有的performance_schema项,性能下降10%。
1 | update setup_instruments set enabled='YES', Timed='YES' where name like '%wait/io/file/innodb/innodb_log_file%';-- redo log |
可以通过max_timer的值来判断数据库是否出问题。假设单次IO请求时间超过200毫秒属于异常:
1 | select event_name,max_timer_wait from performance_schema.file_summary_by_event_name where event_name in ('wait/io/file/innodb/innodb_log_file','wait/io/file/sql/binlog') and max_timer_wait>200*1000000000; |
发现异常后,取到需要的信息,把之前的统计信息清空,这样如果后面的监控中,再次出现这个异常,就可以加入监控累计值了(??):
1 | truncate table performance_schema.file_summary_by_event_name; |