分区表定义
1 | create table 't' ( |
这个表包含了1个.frm文件和4个.ibd文件,每个分区对应一个.ibd文件。
- 对于引擎层来说,这是4个表;
- 对于server层来说,这是1个表。
分区表的引擎层行为
InnoDB
| sessionA | sessionB | |
|---|---|---|
| T1 | begin;select * from t where ftime=’2017-5-1’ for update; | |
| T2 | insert into t values(‘2018-2-1’,1);(Query OK)insert into t values(‘2017-12-1’,1);(blocked) |
初始化表t的时候,只插入了两行数据,ftime的值分别是’2017-4-1’和’2018-4-1’。sessionA的select语句对索引ftime上这两个记录之间的间隙加了锁。如果是普通表的话,T1时刻,在表t的ftime索引上,’2017-4-1’和’2018-4-1’这两个记录之间的间隙是会被锁住的。sessionB的两条插入语句应该都要进入锁等待状态。
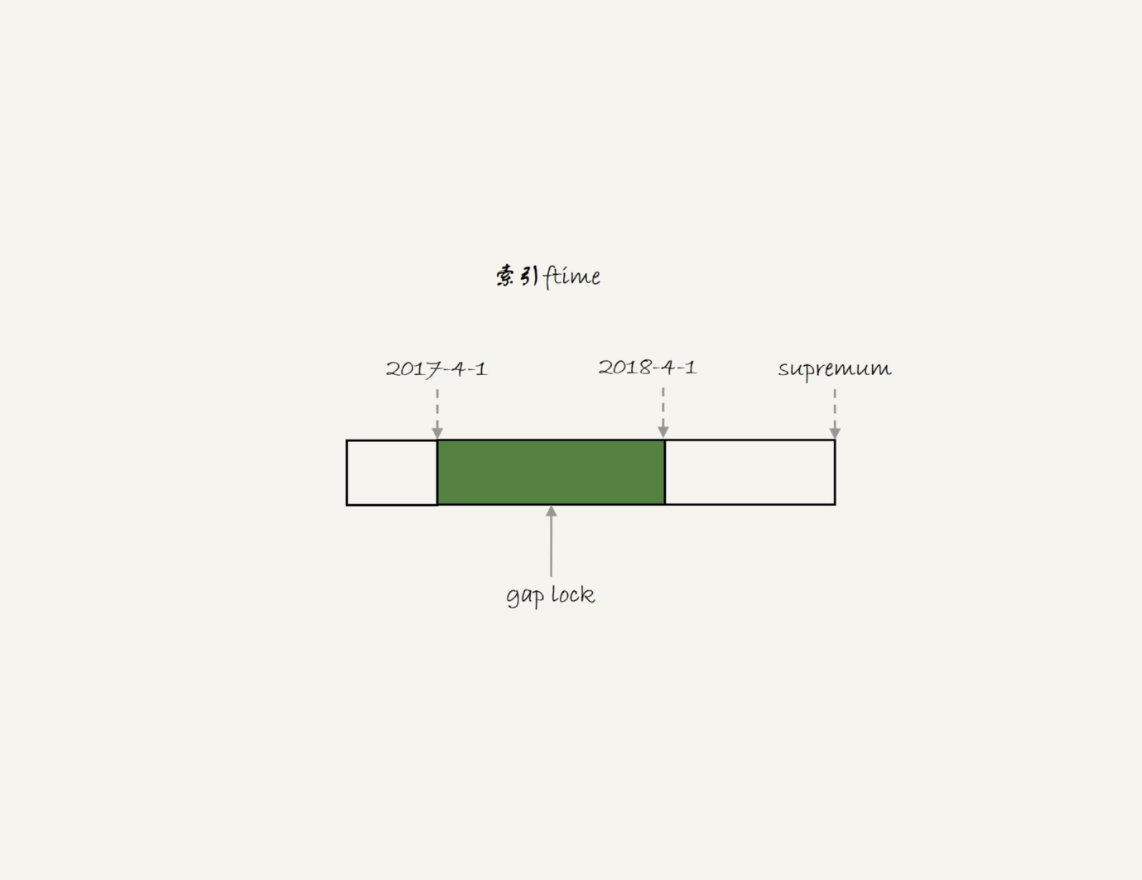
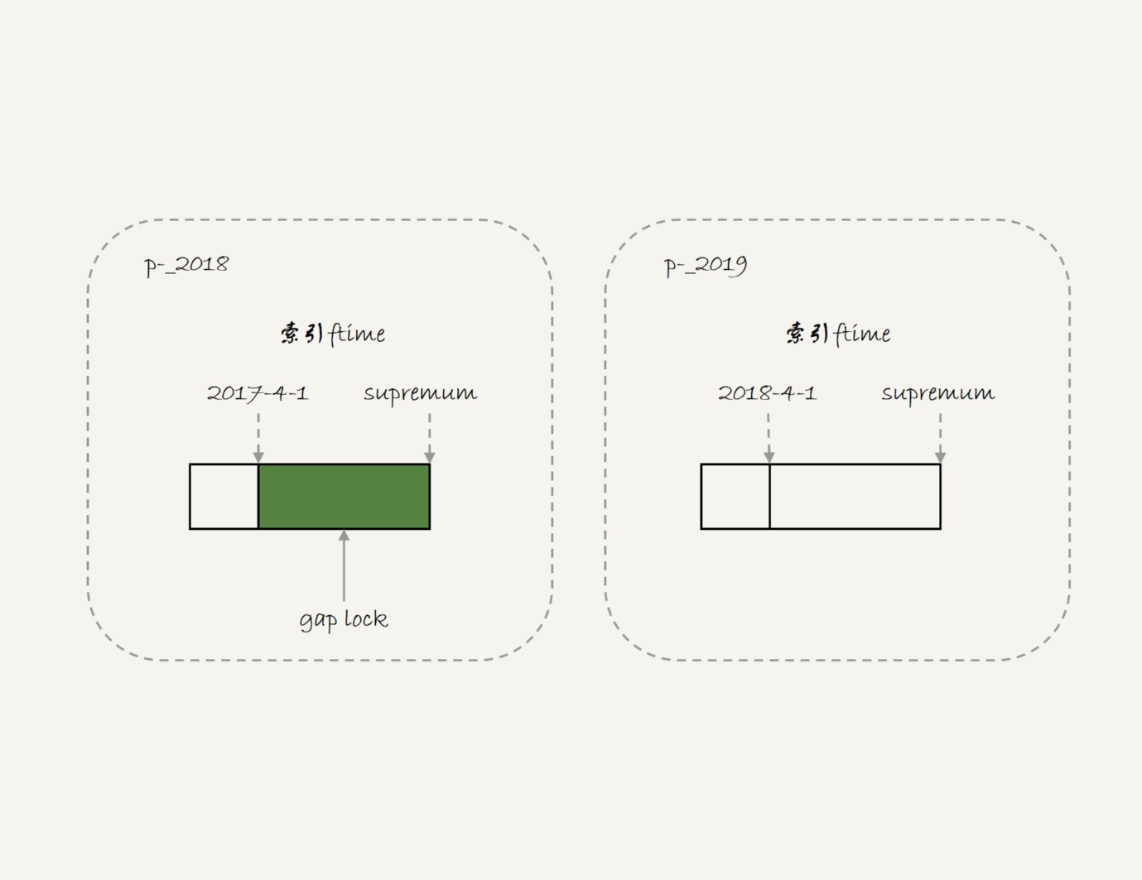
而分区表,对于引擎来说,p_2018和p_2019是两个不同的表,2017-4-1的下一个记录并不是2018-4-1,而是p_2018分区的supremum。表t的ftime索引上的间隙锁范围是’2017-4-1’和’supremum’之间的间隙。所以sessionB要写一行ftime是2018-2-1的时候是可以成功的,而要写入2017-12-1这个记录,就要等sessionA的间隙锁。
show engine innodb status的部分结果:
——- TRX HAS BEEN WAITING 5 SEC FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 24 page no 4 n bits 72 index ftime of table ‘test’.’t’ /* Partition ‘p_2018’ */ trx id 1304 lock_mode X insert intentin waiting
Record lock, heap no 1 PHYSICAL RECORD: n_fields 1; compact format; info bits 0
0: len 8; hex 73757072656d756d; asc supremum;;
MyISAM
alter table t engine=myisam;把表t改成MyISAM表。
| sessionA | sessionB |
|---|---|
| alter table t engine=myisam;update t set c=sleep(100) where ftime=’2017-4-1’; | |
| select * from t where ftime=’2018-4-1’;(Query OK)select * from t where ftime=’2017-5-1’;(blocked) |
MyISAM引擎只支持表锁,sessionA中的update语句会锁住整个表t上的读。sessionB的第一条查询语句可以正常执行,第二条语句才进入锁等待状态。
MyISAM的表锁是在引擎层实现的,sessionA加的表锁,其实是锁在分区p_2018上,只会堵住在这个分区上执行的查询,落到其他分区的查询是不受影响的。
手动分表
不使用分区表的话,需要使用手动分表的方式,避免单表过大。
按照年份来划分,分别创建普通表t_2017、t_2018、t_2019。手工分表的逻辑,也是找到需要更新的所有分表,然后依次执行更新。在性能上,这和分区表没有实质的差别。
分区表和手工分表,一个是由server层来决定使用哪个分区,一个是由应用程代码来决定使用哪个分表。从引擎层看,这两种方式是没有差别的。
这两个方案的区别,主要是在server层上。分区表的问题:打开表的行为。
分区策略
每当第一次访问一个分区表的时候,MySQL需要把所有的分区都访问一遍。一个典型的报错情况是:如果分区表的分区很多,超过了1000个,而MySQL启动的时候,open_files_limit参数使用的是默认值1024,那么就会在访问这个表的时候,由于需要打开所有的文件,导致打开表文件的个数超过了上限而报错。
例:insert into t_myisam values(‘2017-4-1’,1);
ERROP 1016 (HY000): Can’t open file:’./test/t_myisam.frm’ (errno: 24 - Too many open files)
这条insert语句,明显只需要访问一个分区,但语句却无法执行。
使用InnoDB引擎的话,并不会出现这个问题。在InnoDB引擎打开文件超过innodb_open_files这个值的时候,就会关掉一些之前打开的文件。即使分区个数大于open_files_limit,打开InnoDB分区表也不会报“打开文件过多”这个错误,就是innodb_open_files这个参数发挥的作用。本地分区策略的优化。
MyISAM分区表使用的分区策略,称为通用分区策略(generic partitioning),每次访问分区都由server层控制。
MySQL5.7.9,InnoDB引擎引入了本地分区策略(native partitioning)。这个策略是在InnoDB内部自己管理打开分区的行为。优化:如果文件数过多,就会淘汰之前打开的文件句柄(暂时关掉)。
MySQL5.7.17,将MyISAM分区表标记为即将弃用(deprecated)。
MySQL8.0,不允许创建MyISAM分区表,只允许创建已经实现了本地分区策略的引擎。只有InnoDB和NDB这两个引擎支持了本地分区策略。
分区表的server层行为
从server层看,一个分区表只是一个表。
| sessionA | sessionB |
|---|---|
| begin;select * from t where ftime=’2018-4-1’; | |
| alter table t truncate partition p_2017;(blocked) |
show processlist;
| id | user | host | db | command | time | state | info |
|---|---|---|---|---|---|---|---|
| 1 | root | localhost:xxxxx | test | Sleep | 219 | null | |
| 2 | root | localhost:yyyyy | test | Query | 221 | waiting for table metadata lock | alter table t truncate partition p_2017 |
| 3 | root | localhost:zzzzz | test | Query | 0 | starting | show processlist |
虽然sessionB只需要操作p_2017这个分区,但是由于sessionA持有整个表t的MDL锁,就导致了sessionB的alter语句被堵住了。分区表,在做DDL的时候,影响会更大。如果使用的是普通分表,在truncate一个分表的时候,肯定不会跟另外一个分表上的查询语句出现MDL锁冲突。
分区表的应用场景
分区表的优势是对业务透明,相对于用户分表来说,使用分区表的业务代码更简洁。分区表可以很方便的清理历史数据。
如果一项业务跑的时间足够长,往往就会有根据时间删除历史数据的需求,这是按照时间分区的分区表,可以直接通过alter table t drop partition…这个语法删掉分区,从而删掉过期的历史数据。
alter table t drop partition…操作是直接删除分区文件,效果跟drop普通表类似。与使用delete语句删除数据相比,优势是速度快、对系统影响小。
总结
MySQL支持范围range分区、hash分区、list分区等分区方法。
- MySQL在第一次打开分区表的时候,需要访问所有的分区;
- 在server层,认为这是同一张表,因此所有分区共用同一个MDL锁;
- 在引擎层,认为这是不同的表,因此MDL锁之后的执行过程,会根据分区表规则,只访问必要的分区。
必要的分区,根据SQL语句中的where条件,结合分区规则来实现。where ftime=’2018-4-1’,只访问p_2019这个分区。where ftime>=’2018-4-1’,则访问p_2019和p_others这两个分区。
如果查询语句的where条件中没有分区key,那就只能访问所有分区。当然业务分表的方式,同样如此。
如果使用分区表,不要创建太多的分区。
- 分区并不是越细越好。实际上,单表或者单分区的数据一千万行,只要没有特别大的索引,对于现在的硬件能力来说都是小表。
- 分区不要提前预留太多,在使用之前预先创建即可。如果按月分区,每年年底时再把下一年度的12个新分区创建上即可。对于没有数据的历史分区,要及时的drop掉。
查询需要跨多个分区取数据,查询性能比较慢,不是分区表本身的问题,属于数据量的问题或使用方式的问题。
分区表创建自增主键
由于MySQL要求主键包含所有的分区字段,所以肯定是要创建联合主键的。
(ftime,id)还是(id,ftime):
从利用率上来看,应该使用(ftime,id)这种模式。因为用ftime做分区key,说明大多数语句都是包含ftime的,使用这种模式,可以利用前缀索引的规则,减少一个索引。
1 |
|
InnoDB引擎,要求至少有一个索引,以自增字段作为第一个字段,需要加一个id的单独索引。
1 |
|